In the previous post we gave a briefly mentioned the models that we would try and described the dataset on which we shal test of finetuned results.
In this post, we shall discuss the finetuning of a GPT-2 model for conditional keyword generation.
GPT-2, the successor to GPT is a transformer -based language model developed by OpenAI. While it was designed to predict the next word based on the previous words in a text, it has been shown to be capable of producing convincing synthetic texts that garnered a ‘credibility score’ of 6.91/10 (actually 6.07 in the model we used, but more on that in a bit) as evaluated by a survey at Cornell University.
The original model (with 1.5 billion parameters) was trained on a dataset of roughly 8 million text-documents from the internet and is curated to have the diversity that represent the naturally occurring diversity over multiple domains. Initially, there was a concern that the original model could be misused for generating synthetic texts catered towards synthetic propaganda. When it was released, the concern died due to lack of evidence of such exploitations. However, due to constraints (primarily computation but not limited to), we use a smaller model with 124 million parameters$^1$.
It is unwieldy to discuss the general transformer architecture here (great lecture here) , and also you cannot modify the GPT-2 architecture and hence for the purpose of this post, we shall take it as a black box. Since the original GPT-2 did not have any protocol to finetune the model, Neil Sheppard$^2$ and then Max Woolf$^3$ forked the existing model to create a finetune and generate pipline which we have used in this project.
Controlled Generation
Let us address two limitations of the original GPT-2 model:
- It was originally designed to generate long-form text until it reaches the prescribed length. Therefore, it is not suitable to generated shorter text (like a quick review).
- With the exception of the starting cue, the generation was uncontrolled, meaning there is no way to enforce the presence of a keyword or context in the generated text.
The first drawback is addressed by introducing a <|startoftext| > and <|endoftext|> token at the beginning and end for each instance of the dataset and then instructing the model to terminate the generation once that particular token has been generated. This introduction of start and end token, along with the length of the text, is capable of producing shot-form complete texts.
The second limitation (which is also the crux of our project) is addressed in a similar fashion, by appending additional tokens as `[coarse conditioning]^[fine conditioning] (`, ^ as the delimiters) to each instance of the dataset.
We obtain the keyord following the procedure in the previous post, Then we convert the the dataset into a .txt file and feed it to the finetuning code.
Finetuning the model (and generation)
Once we have the keyword in the required format, we can proceed to finetuning by running the code
sess = gpt2.start_tf_sess()
gpt2.finetune(sess,
dataset=filename,
model_name='124M',
steps=100,
restore_from='latest',
run_name='run1',
print_every=100,
sample_every=100,
save_every=100,
overwrite=True
) All finetuned model checkpoints are stored in run_name, and the model saves a new checkpoint every save_every, samples from the most recent weights sample_every steps and prints to screen print_every steps. Different run_name can be used to experiment with different sets of keywords and/or datasets. Also one can resume a halted training process either from different checkpoints or the latest one as mentioned in the restore_from parameter.
Here are some snippets of the training process,
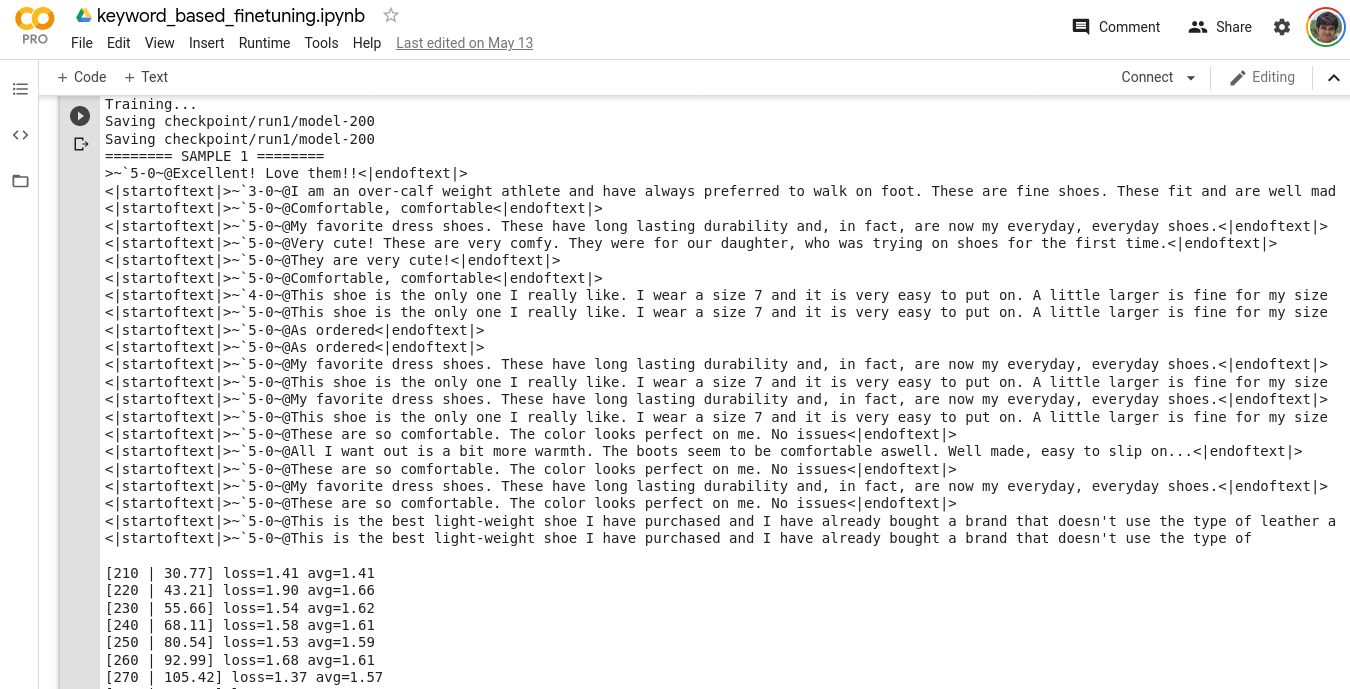
As you can see, the samples are mostly 5 star ratings (due to the inherent data imbalance), however towards the end,
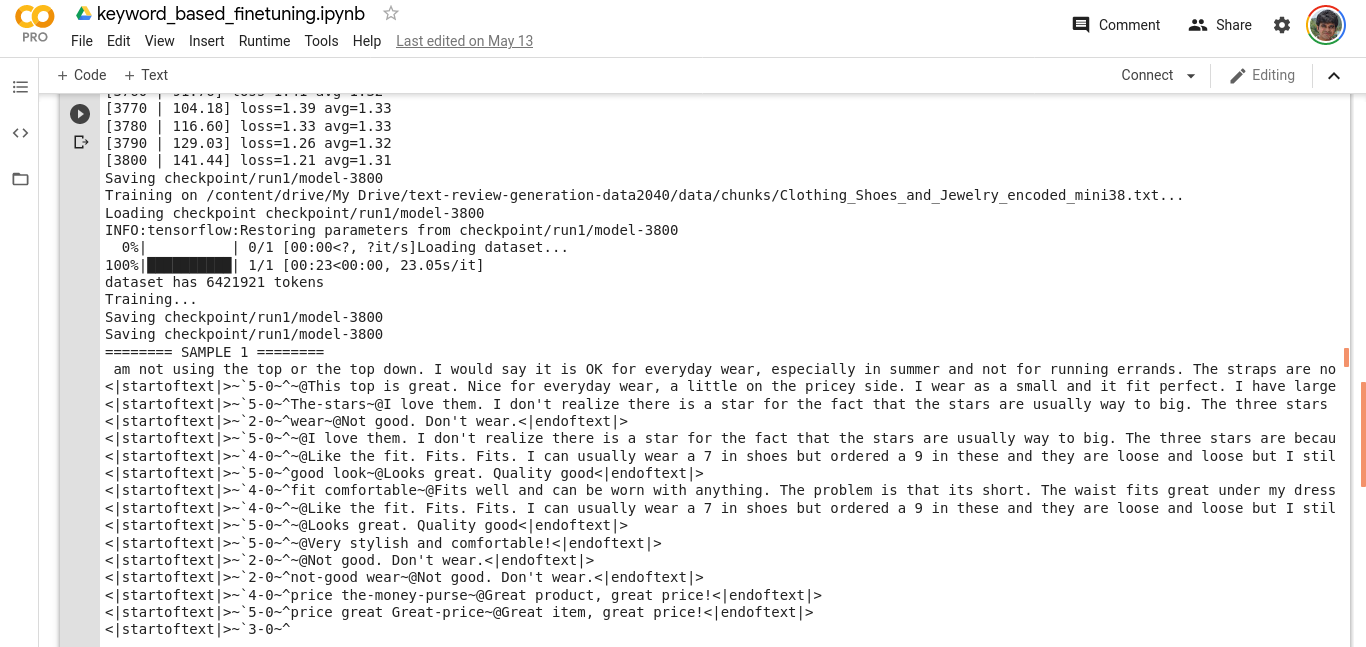
the loss is lower (remember that we are finetuning, so not much is expected), and now since the model has see a lot more 3’s and 4’s, the generation is more robust. A thing to note here, is that if you do not have a large dataset to finetune, the model may end up overfitting and hence it us advisable to keep finetuning epochs to a minimum (like 1-10). Or stop the process once the change in loss plateaus.
At the end of the finetuning, you can generate samples from the finetuned model, by running
sess = gpt2.start_tf_sess()
gpt2.load_gpt2(sess)
gpt2.generate(sess,
temperature=0.7,
top_k=40,
nsamples=5,
batch_size=1,
length=200,
prefix="<|startoftext|>~`3~^Belt ~@",
truncate="<|endoftext|>",
include_prefix=False,
sample_delim=''
)For this, we can use both top k sampling as well as top p (nuclues sampling), whatever works better for dataset of interest. We could also play with the temperature parameter to play with the creativity/sensibility (a variant of the bias/variance) trade-off.
Please note the naiveity in this approach, which can best understand what's going on by considering the following scenario:
Real life:
Professor to Student: This project is an absolute garbage.
(this clearly is a negative sentiment say 1.0 and the keyword is project)
Finetuned GPT-2 life:
Professor to Student:<|startoftext|>`1.0^project~@This project is an absolute garbage.
What is really happening is that we are training the model (falsely) to believe that normal text, is always spoken such that you declare your sentiment and keywords before saying the sentence out.
So then we can leverage GPT-2's starting prompt ability to condition the generating apriori by adding the keyword to the starting prompt.
Generated Samples
Rating: 1, Keyword: Belt
Very thin fabric. Material is super thin. Not much give in the waist. The belt is pretty thin. I am a size 6-8, and the 6-8 fit me perfectly. I wear a size 7 dress, but the 6-8 was too tight and the length was too short for me. I was really disappointed with the purchase.
Rating: 3, Keyword: Belt
purchased a belt with a buckle, which I thought was a nice addition. Unfortunately, the buckle broke. I had to glue it back together. If you have a small wrist, you might be able to use it, but if you have a larger wrist, you might not be able to use it.
Rating: 5, Keyword: Belt
Belt fit perfectly. Very happy with this purchase. Very comfortable. The fit is perfect.
Rating: 1, Keyword: Boot
Boots are very heavy and have no traction on the bottom of the foot. The soles are thin and hard, they are not able to hold up to the very high price. I have ordered two different sizes for my son and they have the same problem. He can not wear them. We cannot find ones that have the sole.
Rating: 3, Keyword: Boot
Comfortable. But the leather has a different color to it, and I know that the black will fade, so I am not sure if the leather is the same color. I do not know if this was the only issue.
Rating: 5, Keyword: Boot
Nice boots and very comfortable. The color is very nice and the fit is very flattering.
Next Up
The approach here is naive in the sense that there is no mathematical basis behind the generation except the obvious biasing of the text. The examples above were cherry picked and roughly every 1 out of 5 generated text is an interesting one. The dataset was also unbalanced towards more 5 star rating and directly affects the quality of the generation by creating sampling bias. Finally, the delimiters of the coarse and fine conditioning keywords were chosen based on relatively rarely used ASCII characters, still one can be disciplined about it by incorporating the base delimiters of GPT-2$^{4,5}$.
As our next step, we shall attempt to decouple the types of conditioning by investigating two other conditional language model - PPLM and CTRL, where the former would be used to generate rating based reviews solely and the latter would be used for generating text pertaining to a broad category - for eg. reviews specific to clothing or to amazon prime videos. Depending on the quality of text generated by the two models, we shall zero-in on our final model.
All codes for the project can be found in this github repository
References
References