With all the strength of the finetuned GPT-2 model, the most state of the art model is far too large and inaccessible to implement and re-train to the particular specifications of a new task. In order to create reviews that work particularly well with respect to generating a particular sentiment, we decided to take the next step and build on GPT-2 using Uber’s PPLM algorithm.
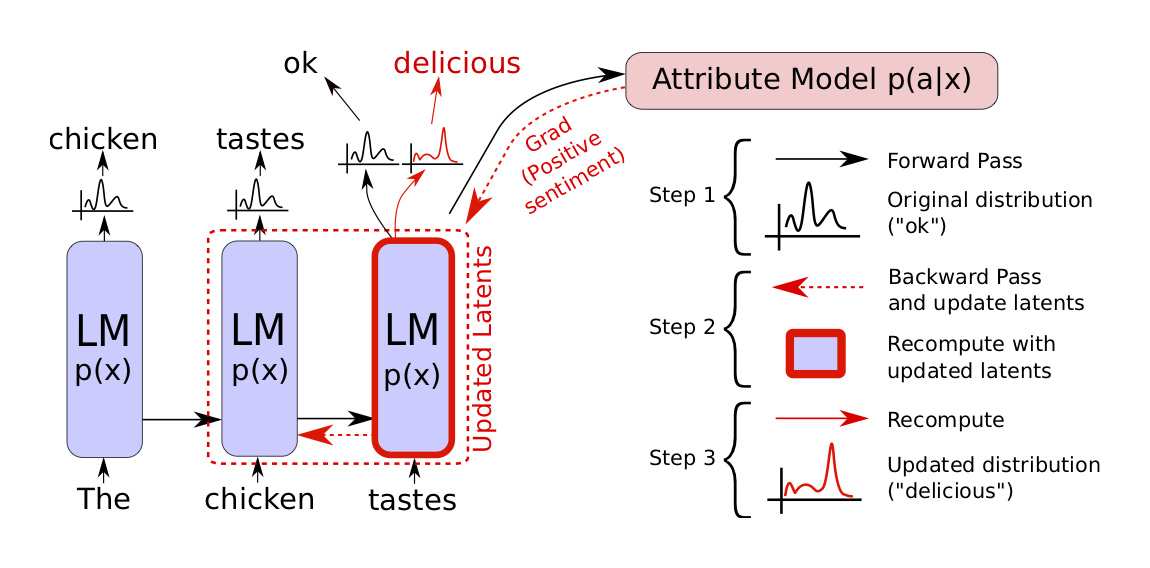
PPLM, short for Plug and Play Language Model, is a model developed to steer and control successful language models to complete more specified tasks, such as discussing a particular topic or containing a specific sentiment (positive or negative). For example, while GPT-2 is fantastic at encoding information about speech patterns, grammar, and spelling, we would be unable to force GPT-2 to generate a positive sentence given a negative starting text, such as “the food is awful”. Instead, PPLM is able to build on top of GPT-2 in order to create a positive conclusion to a negative sentence, such as: “The food is awful, but there is also the music, the story and the magic! The “Avenged Sevenfold” is a masterfully performed rock musical that will have a strong presence all over the world.”

PPLM allows us to have flexibility in choosing simple attribute models that represent what we want to control, and plug it into a large, unconditional language model. What makes PPLM so special is that there is no training or fine-tuning required of the large language model — this allows users to utilize the top of the line language models available, even if they do not have the resources to required to train them. The largest and most successful publicly available language models contain up to a billion parameters, take unfathomable amounts of money and resources to train, and often do not provide the training data publicly. On the other hand, these plug-in attribute models may be many orders of magnitude smaller in size. Uber uses the metaphor that these huge language models are like a wooly mammoth that lumbers around aimlessly, and the plug-in attribute model acts as a tiny mouse that sits on the mammoth and guides it.
We specifically implemented PPLM-Discrim, where the plug in attribute model on top of GPT-2 is a single layer discriminator with the sole purpose of discriminating between positive and negative sentiments. In other words, this discriminator layer takes the mean of the embedded representation output from the original GPT-2 model and predicts the final output label of rating. In this particular scenario, that is encoded by the ratings associated with the reviews, ranging from most negative at 1, and most positive at 5.
Results of PPLM-Discrim
After training, we could now use the PPLM source code to run an example based on the pretrained GPT-2 model and our trained sentiment rating discriminator. Below is an example of the code that we run to generate the review text. In terms of hyperparameter tuning, there were two that we had to adjust in order to produce the desired results. Firstly, the parameter stepsize is used to specify the degree of topic control. The higher we increase stepsize, the more topic control is intensified, whereas the lower it is, the softer the topic control. Secondly, we input parameter class_label in order to specify which sentiment we want for our review text output, corresponding to the “rating” label from the data.
run_pplm_example(cond_text='This food',
pretrained_model='gpt2',
discrim_weights='generic_classifier_head_epoch_1.pt',
discrim_meta='generic_classifier_head_meta.json',
discrim='generic',
class_label='1', length=50,
stepsize=0.90,
sample=True, num_iterations=1,
gamma=1, gm_scale=0.9,
kl_scale=0.02,
verbosity='quiet')Example Reviews for Different Sentiments
Here is a hand-picked example of the review data. We show this as our result as this type of qualitative, human judgment on the text data is the best way to evaluate it’s effectiveness, as ultimately we desire our reviews to be able to convince a human that another human wrote them. With the initial start of sentence text as:
= Prefix of sentence = <|endoftext|>This food
The baseline review output from the pretrained GPT-2 model before any sentiment control was:
= Unperturbed generated text = <|endoftext|>This food is delicious! It tastes like real chicken, but has an amazing flavor! It's so good that I don't even have to eat it in a restaurant. It tastes like rice and the texture is so delicious! It's also a great option to
The review text output corresponding to a rating label of 1 is:
= Perturbed generated text = <|endoftext|>This food-safety inspector warned this year that the industry warned of health hazards of the tainted rice paste. The rice paste paste made by B.C. rice producer Bao Dong was used in a fatal accident in Surrey, B.C.,
The review text output corresponding to a rating label of 3 is:
= Perturbed generated text 2 = <|endoftext|>This food safety report found a "significant increase" in food safety concerns. The report will be considered in the House committee hearing on the committee's report at 3:30pm on Friday, June 8.
The review text output corresponding to a rating label of 5 is:
= Perturbed generated text 3 = <|endoftext|>This food is fantastic as a great breakfast, an easy meal, and will keep you full for up to 3 weeks. I've also found this recipe makes very tasty meals for 2 weeks or more after eating without refrigeration. It's delicious and nutritious too.
From multiple different trials with a variety of starting sentence tokens, we were excited to find that we would consistently see clearly negative sentiment associated with class labels of 1, and see clearly positive sentiment associated with class labels of 5. We did notice that our PPLM-Discrim model did have an easier to producing accurate class 5 reviews, but sometimes would produce more positive reviews even for lower rated classes. This likely is because of the class imbalance of the data. This could be solved by taking a stratified sample of the data so that all classes are equally represented in the training data. Looking at example of class label 3 text was interesting, because it is relatively hard for humans to specify exactly what “neutral” text is.
Rating 3 Texts Gave Interesting Neutral Results
A lot of class 3 text came out to be neutral in the sense that the text discussed things like inherent properties or details of the subject, like the size specifications of a piece of clothing, or it discussed the scientific compositions and names of the chemicals related to the subject. For example:
= Perturbed generated text 1 = <|endoftext|>Potato chips are usually boiled in water in boiling water in an orange coloration apparatus (a color of food coloring oil or vegetable oil). The color of the coloring of potato chips are usually orange or brown depending upon whether their colors are yellow, purple or yellowish.
= Perturbed generated text 2 = <|endoftext|>These shoes are made of polypropylylyleyl acetate (PPAR) and polypropylene poly polyethylene polypropyl acetate (PUPA). The sole was then hand washed with polyethylene.
Controlling Sentiment
Furthermore, we can confirm that we have a higher capability of controlling the sentiment outcome of the sentence, even if we provide the model with a start of sentence with the opposite sentiment. For example, for the input:
= Prefix of sentence = <|endoftext|>This dress is tight
We get the review text output corresponding to a rating label of 5:
= Perturbed generated text = <|endoftext|>This dress is tight, but flattering and cozy, and flattering. This dress is perfect for weddings or other events that require a little attention to detail.
On the other hand, we can give the model a positive sentiment start of sentence and ask for a rating label of 1 text. For the input:
= Prefix of sentence = <|endoftext|>The shirt is nice
We get the review text output:
= Perturbed generated text = <|endoftext|>The shirt is nice, but it does not have a collar or a small picture of the logo on the back. I am not sure what is on the back. It looks too expensive shirt and the sleeves are too thin but my boyfriend and the mother who owns it looks awesome.
Future work and CTRL
Finally, we have now been able to generate text reviews based on a keyword topic, and based on a particular sentiment. Next we shall briefly explore another model that is trained to condition on a “control code” that specifies the domain, entities, and relationships between entities in the generated text. Control codes can derived from structure that naturally occurs in raw text (eg. Reviews, Links etc.. We attempt to do this using Salesforce’s CTRL algorithm.
When attempting to fine-tune the Salesforce model for new control codes, we encountered two connected problems. The first was the model’s failure to provide a prompt for the control code and starting input during the generation process. We eventually traced this back to the second problem, an error in the training process. Even with our smallest-sized data set, the training process quickly used up all of the GPU’s memory (within 30 seconds). This problem persisted even when we used a pretrained control code for reviews and migrated the generation environment from Colab to Google Cloud Platform. Luckily, however, there exists a lower-memory usage version of the model that we used instead.
There also exists a pre-existing (and pre-trained) control code called Reviews, which we demostrate here:
Rating label of 1 is:
= This book is just another example of how to make money off of people who are gullible enough to believe in psychics. Rating: 1.0
= I found this book to be poorly written and full of errors. Some sentences don’t even make sense. Don’t waste your time or money! Rating: 1.0
= Not what I expected. Very short read. No real information provided. Would like more info on the subject. Rating: 1.0
Rating label of 5 is:
= This item works as advertised. My wife uses it to listen to music on her phone while she works. Shes has had no problems with it, so far. Rating: 4.0.
= Good quality sound from such small speakers. Easy to use and set up. Rating: 4.0
= I love these. I can take them anywhere and put them wherever I want. And they don’t cost much. Rating: 4.0
It is interesting to note that in the case of the Rating: 5 prompt, all of the generated reviews actually included ratings of 4.0. This might be due to an imbalanced lack of 5.0 ratings in the training set or just random variation.
CTRL’s generated reviews were well-formed and stayed on topic, especially when compared to the more primitive results from the GPT-2 model.
Compared to the other models we researched, CTRL has the downside of not allowing as granular control of the generated review. This means that we can only specify the general domain of the review, not the actual entity mentioned (in this case, the product). For example, we can specify “clothing” as the domain and provide a starting input of “The belt is…”, but we cannot ensure that “belt” will be the main entity described by the text. In addition, CTRL is a very large model and is difficult to train and host for generation on a local machine. We were only able to use the modified version in which all of the parameters are converted from 32-bit types to 16-bit types. It is therefore impractical to use for most everyday situations (i.e., it could not be easily embedded in a Dash web app).
To be more successful with CTRL in the future, we would investigate ways to introduce a notion of a specific entity into the CTRL generation process. One simple way to do this would be to create separate control codes for “BeltReview” and “ShirtReview” using separate training sets. This would require much more data than we currently have access to or the tools to manipulate efficiently.
All codes for the project can be found in this github repository
References
- Dathathri, Sumanth, et al. “Plug and Play Language Models: A Simple Approach to Controlled Text Generation.”, International Conference on Learning Representations 2020, 3 Mar. 2020,https://arxiv.org/abs/1912.02164.
- https://github.com/uber-research/PPLM
- https://github.com/salesforce/ctrl