Natural Language Processing (NLP) is the study of representation and analysis of human language in the format of computer readable vectors which encode a given language elements as a multi-dimensional vector of real numbers between 0 and 1.
Natural Language Synthesis is a sub-field of NLP where the challenge is to develop algorithms to stitch these machine represented words in a way such that when they are re-translated back to language elements, it is coherent. An element of a ‘good’ sentence is the ability to stay in context over long stretch of lines (and even paragraphs). A good model should also be able to initiate new context without being restricted to the past flow of conversations.
While generating ‘human-like’ text is a solved problem, controlling the content of the output based on a user-defined context is still an open challenge and an active research area. Our target in this project is to study the possibility of generating product reviews based on a given set of keywords.
In this series, we shall discuss finetuning 3 models — GPT-2, PPLM and CTRL, to acheive conditional text generation. In the rest of the post, we shall overview the mathematical basis of our target. We shall also discuss the dataset on which we tested our models.
A bit of Maths
To understand the basic mechanism behind the factors that steer the context, it is useful to review a bit of the standard language modelling and then discuss the modifications over it.
Given a sequence of tokens $X = \{x_o,x_1,\dots,x_m\}$, such that each comes from a fixed set of symbols (a sentence which a fixed set of words), the target of a language model is to estimate . Considering that each to be a part of a sequence, we can factorize the distribution as the following product
$$ \begin{equation*} p(x) = \prod_{i=1}^n p(x|x_{< i}) \end{equation*} $$This factorization (mathematically described as a autoregression model) intuitively converts the model into a ‘next-word’ prediction model.
To train the model, we try to map the network to the set of parameters which minimises the negative log-likelihood over the dataset
$$ \begin{equation*} \mathcal{L} = -\sum_{k=1}^{n}\log p_\theta(x_i^k|x_{< i}^k) \end{equation*} $$From this we can then sequentially generate text by sampling from the obtained $p(x)$
The task at hand is to learn the conditional language model $p(x|c)$ where c is the control code that sets the context of the sentence to be generated. The distribution can still be decomposed as before and the loss function is given by
$$ \begin{align*} p(x) &= \prod_{i=1}^n p(x|x_{< i},c)\\ \mathcal{L} &= -\sum_{k=1}^{n}\log p_\theta(x_i^k|x_{< i}^k,c) \end{align*} $$Exploratory Data Analysis
For the trial dataset in this project, we use a subset of the “Amazon Review Data (2018)” dataset created by Jianmo Ni at UCSD, which contains a total of 233.1 million reviews. Our project-specfic dataset is composed of 11,285,464 reviews under “Clothes, Shoes, and Jewelry” category. The dataset is in JSON format. A sample review looks like:
{
"image": ["https://images-na.ssl-images-amazon.com/images/I/71eG75FTJJL._SY88.jpg"],
"overall": 5.0,
"vote": "2",
"verified": True,
"reviewTime": "01 1, 2018",
"reviewerID": "AUI6WTTT0QZYS",
"asin": "5120053084",
"style": {
"Size:": "Large",
"Color:": "Charcoal"
},
"reviewerName": "Abbey",
"reviewText": "I now have 4 of the 5 available colors of this shirt... ",
"summary": "Comfy, flattering, discreet--highly recommended!",
"unixReviewTime": 1514764800
} Preprocessing
Some preprocessing was necessary before we proceeded to our EDA. Firstly, we gave each review an ID and dropped all the features except rating and review text. This allowed us to remove unnecessary information and shrink the size of the dataset considerably.
For the purpose of generating a set of keywords per review, We used SpaCy to generate keywords from the text of the review. In particular, we employed en_core_web_sm which is a small English model trained on written web text (blogs, news, comments), that includes vocabulary, vectors, syntax and entities.
In each each sentence we use the aforementioned model to parse it to identify the follwoing parts of speech (POS): Verb, Proper Noun, Noun, Adjective and Adverb (after removing pronouns and stopwords). For the noun and proper noun, we took the raw form of the word, but for the other parts of speech we lemmatized the text to avoid influencing the tense of the word (to give the model freedom to choose where in the sentence it puts them). We then combined the keyword in to sets of three and shuffled them so that the order of keyword is destroyed and acts as a regularizer. We then pick one word from the set of three keywords as our keywords (pertaining to that review).
It is to be noted that while spaces and punctuations are normalized to dashes, the keywords are not case normalized for a richer experience.
Since the dataset is massive, we use Ray to override the python GIL and leverage all CPU cores to expedite the process.
The code to generate keyword and then append them to the dataset can be done by running
encode_keywords(csv_path='/content/drive/My Drive/text-review-generation-data2040/data/Clothing_Shoes_and_Jewelry_5.tsv',
out_path='/content/drive/My Drive/text-review-generation-data2040/data/Clothing_Shoes_and_Jewelry_5_encoded.txt',
category_field='rating',
title_field='text',
keyword_gen='text') Interesting Trends
The distribution of ratings is left-skewed (negatively skewed). We can see that people generally tend to give 4 and 5 star reviews.
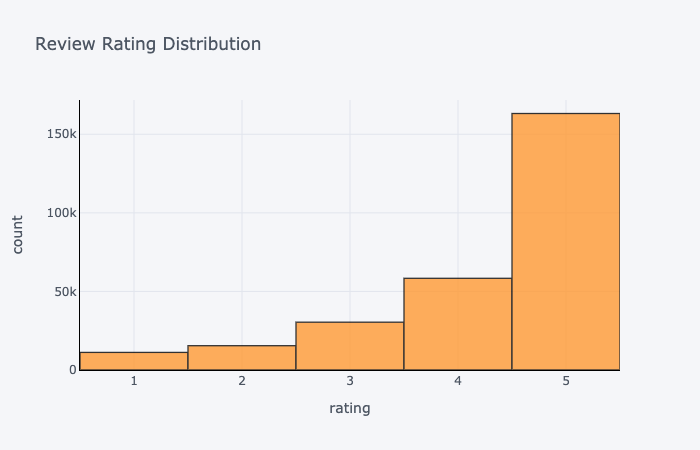
Words and Bigrams
Then, we looked at the most frequent 20 words and bigrams in our reviews.
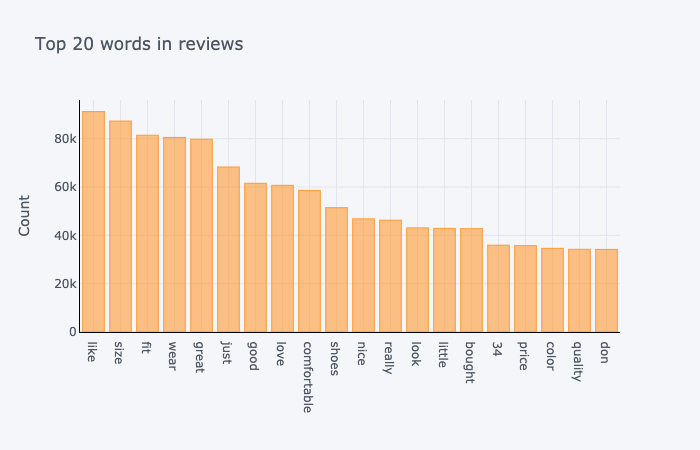
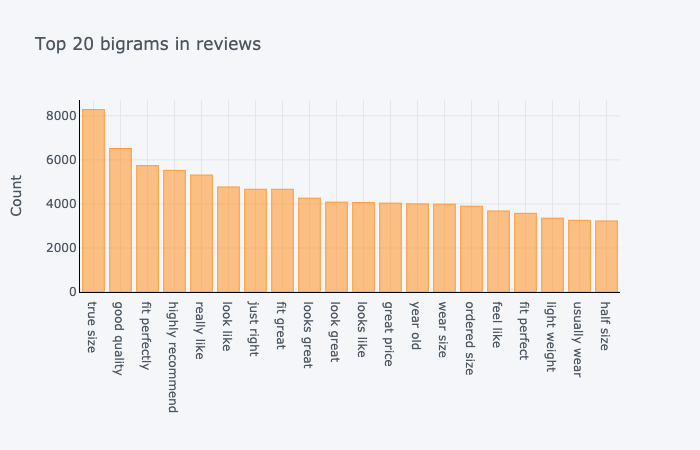
We have that the most frequently used bigrams are a combination of verb and adjective that denotes the quality of the product and how well the product fits to the customer. We have that most bigrams denote positive remarks about the product. Similarly, the most frequently used words are positive adjectives.
Word Cloud by Ratings
Next, using WordCloud library, we looked at the wordcloud of the reviews. First, we plotted the wordcloud of all the reviews, and then we plotted the wordclouds by ratings (rating = 1, rating = 5) to see whether there is a difference in the use of words in the review texts by ratings. We removed the stopwards and plotted the wordcloud accordingly.
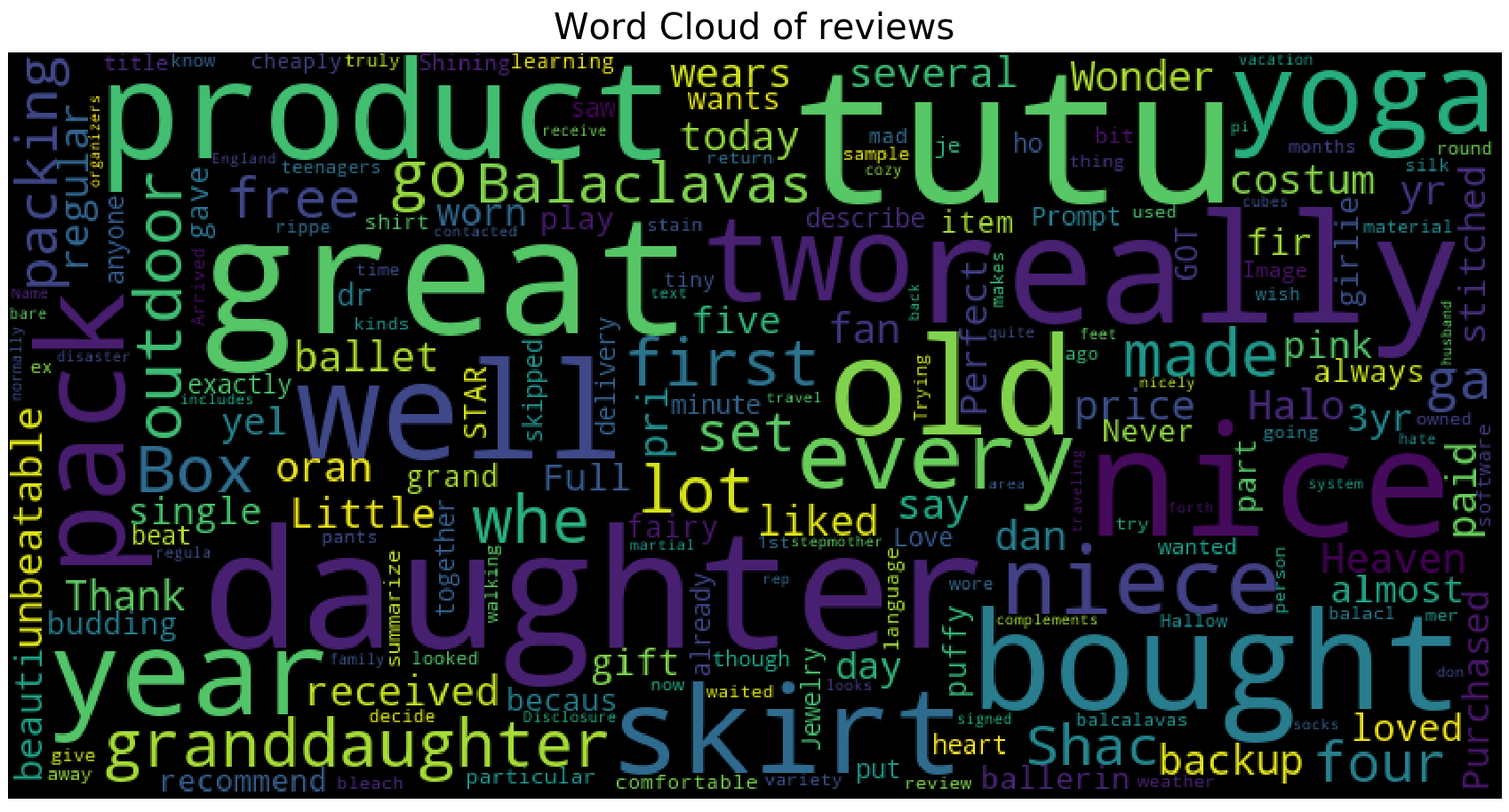
We have that the most commonly used words throughout the reviews include “great”, “well”, product”, “daughter”, “bought”, “tutu”, “nice”, etc..
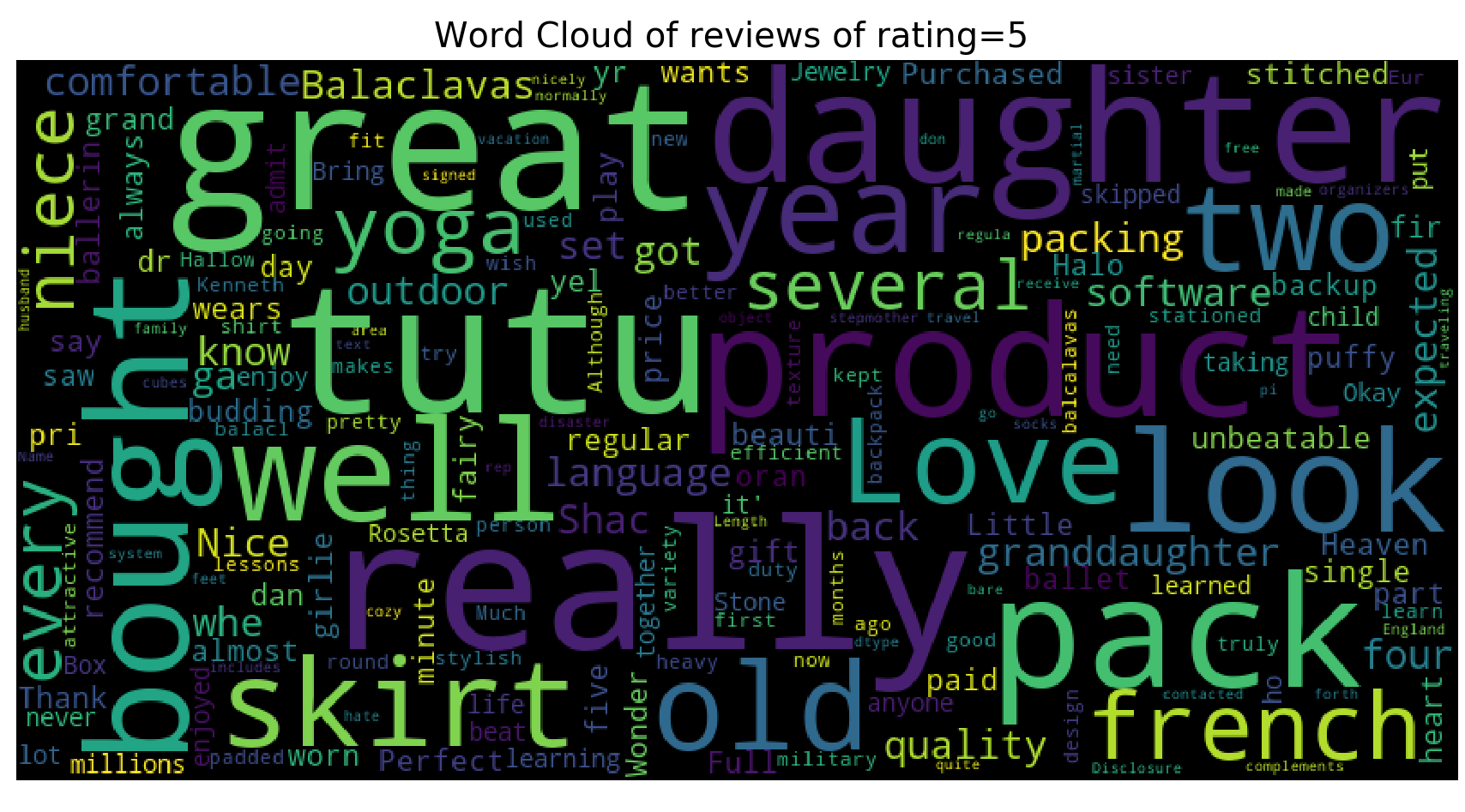
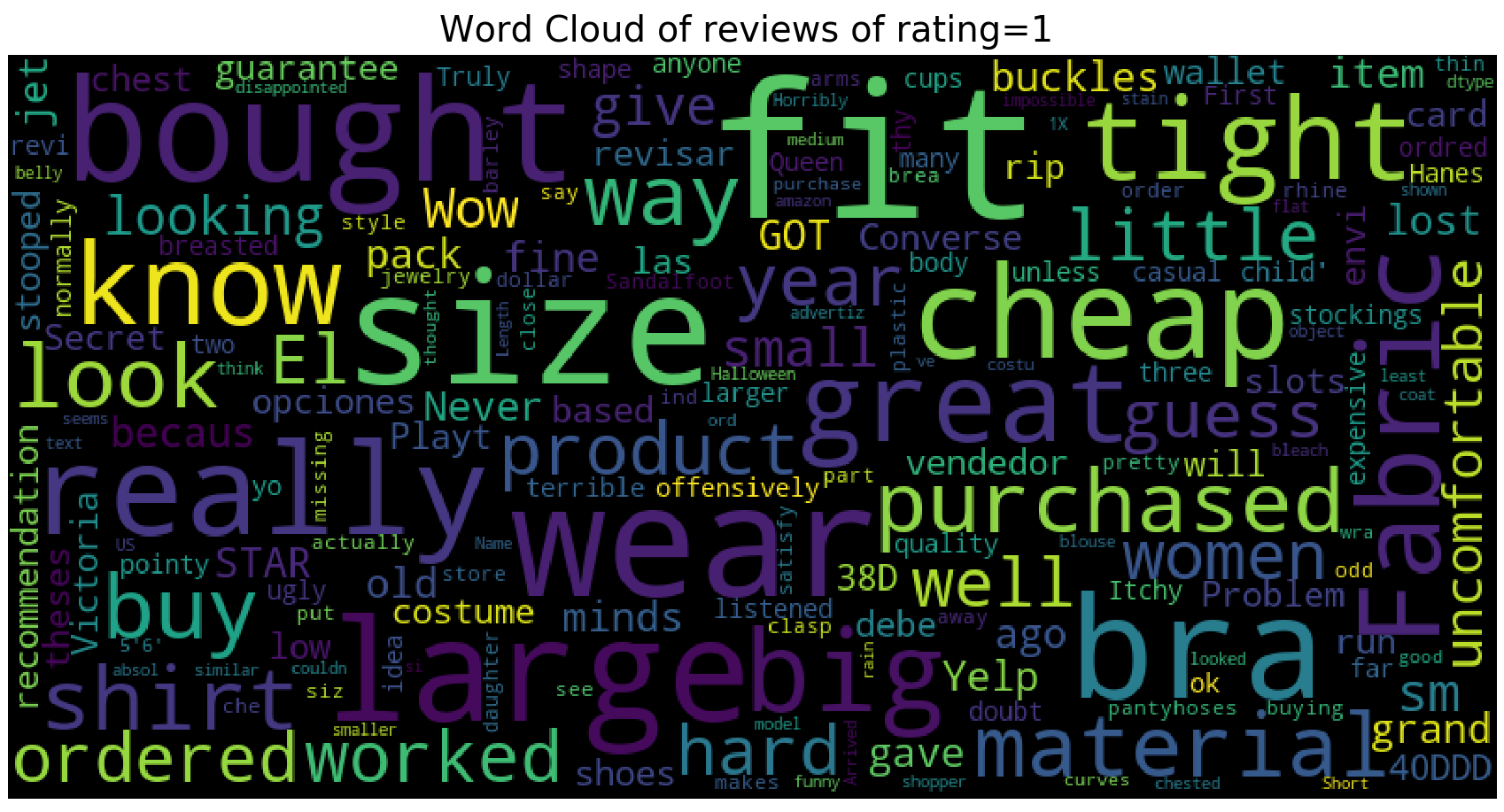
We have that the wordcloud for ratings = 5 is very similar to that of all the reviews. However, for wordcloud for ratings = 1, we see that the most primarily used words are “size”, “fit”, “large”, “big”, “tight”, “cheap”. We can infer that most of 1 star ratings come with dissatisfaction with size (too big or too small).
So far, we have that most of our reviews are positive reviews given the ratings, polarity, and the wordcloud. However, looking at the distribution of the sentiment polarity, it does seem that the general positivity of the reviews are bias from our data. It seems more due to the fact that people are generally satisfied with the products they purchased on Amazon.
Top 20 keywords
Lastly, we looked at the top 20 keywords from our dataset.
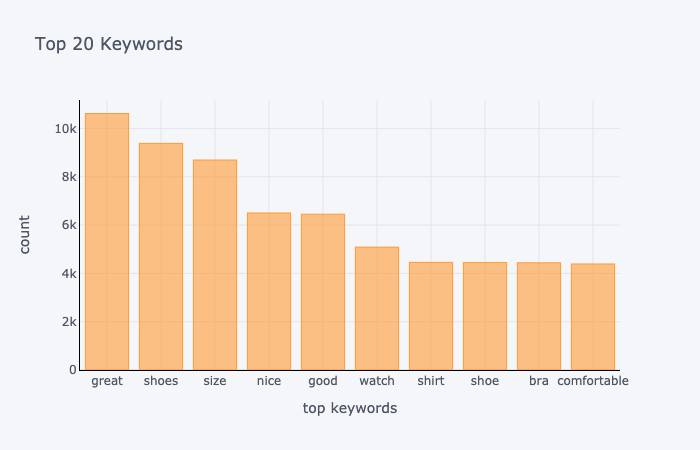
The top 20 keywords include positive adjectives like “great”, “nice”, “good”, “comfortable” and products like “shoes (shoe)”, “shirt”, “bra”.
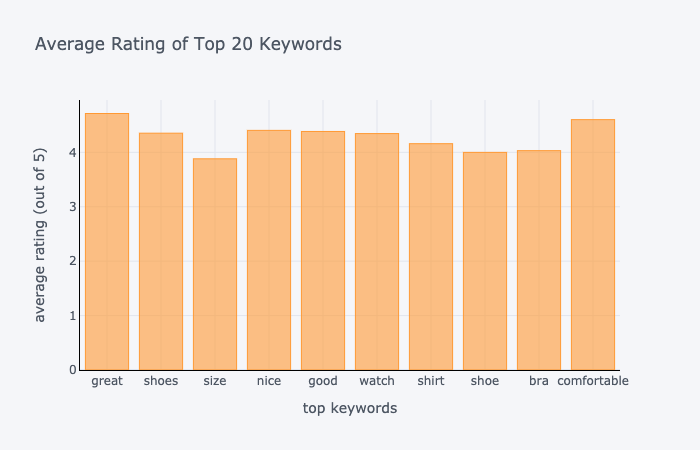
Next, we looked at the average ratings of the keywords. According to our plots, the keywords “great”, “nice”, “good”, “comfortable” have average ratings of above 4. For keyword “size”, the average rating is below 4, which means that most people post reviews of size when they are generally not satisfied (size too big, size too small). Other keywords tell a similar story.
Next Steps
Going forward, we shall now investigate our models on this dataset. We shall start with finetuning GPT-2 model and then investigate PPLM and CTRL both of which are designed particularly for our purpose. See you then.All codes for the project can be found in this github repository
References
- Max Woolf (@minimaxir)
- Jianmo Ni, Jiacheng Li, Julian McAuley, “Justifying recommendations using distantly-labeled reviews and fined-grained aspects”, Empirical Methods in Natural Language Processing (EMNLP), 2019, https://www.aclweb.org/anthology/D19-1018/
- Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, Rosanne Liu, “Plug and Play Language Models: A Simple Approach to Controlled Text Generation”, arXiv Computation and Language, 2019, https://arxiv.org/abs/1912.02164v4
- Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, Richard Socher, “CTRL: A Conditional Transformer Language Model for Controllable Generation”, Salesforce, 2019, https://arxiv.org/abs/1909.05858