নমস্কার !! (Hello in Bengali) , This is Christina (ক্রিস্টিনা) and Sayan (সায়ন), graduate students at the Data Science Initiative, Brown University¹ . As a part of the coursework for DATA 2040 — Deep Learning and Advanced Topics in Data Science, we are working on the Kaggle Competition: Bengali.AI Handwritten Grapheme Classification.
Bengali² (used synonymous to Bangla) ranks in the top 5 spoken languages with more than hundreds of millions of speakers. It is the official language of Bangladesh³ and is the second most spoken language in India (after Hindi). The language has a total of 40 consonants and 10 vowels at its base. However, there can be conjunctive words, which are formed by joining a pair of consonant/vowel (known together as grapheme root). Further additions in the form of another vowel and/or consonant can be achieved by composing the grapheme root with yet another vowel or consonant accent (synonymous to diacritic). This, in total, form a Grapheme.
Grapheme = Grapheme root + vowel diacritic + consonant diacritic.
This complexity results in ~13,000 different grapheme variations (as compared to ~250 in English). Of these, only roughly 1,000 are represented in the training set. Hence focusing on the components to decipher bengali handwriting is important to assemble a Bengali OCR system without explicitly setting recognition rules (in the software 1.0 sense) or obtaining handwriting samples for all 10k+ graphemes.
This is both of ours first attempt at a kaggle competition or designing neural nets in the first place, so forgive us for any errors made in the setup or execution. Irrespective of your expertise/interest in the field of Machine Learning / Deep Learning, feel free to join us in our adventure through the ravines and plains (of the loss function) and we slip and climb our way up to the peak (of the metric). Oh yeah, your comments are highly welcome, please help us get a better score (on the course and the competition).
Here we shall present: the problem statement, description of the data-set with exploratory data analysis, the image processing pipelines, the neural net architecture and results in a series of posts, this being the first of them.
Let’s begin…
Exploratory Data Analysis
As we know, we have 3 targets to predict in this problem (each of which have several different sub-classes as shown below):
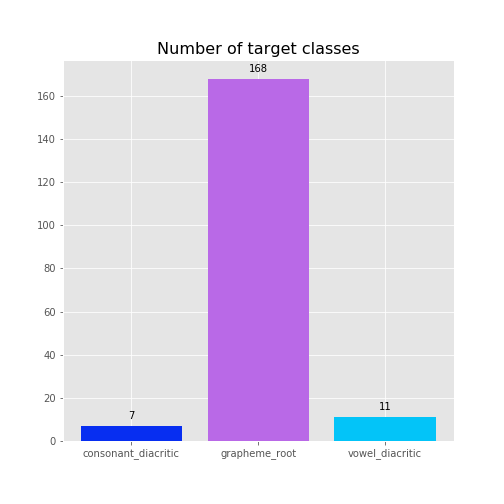
Major Targets:
- Grapheme Root: 168 subtypes (eg. দ্ব, ন, ল্ড, ক্ল, …)
- Vowel Diacritic: 11 subtypes ( eg. ◌া, ি◌, ◌ী, ◌ু , ◌ূ , ◌ৃ , ◌া, ◌ৗ )
- Consonant Diacritic: 7 subtypes (Null, ◌্য (য-ফলা), ◌্র (র-ফলা), র্ ( রফ), ◌ঁ , ◌র্্য ( রফ য-ফলা), ◌্র্য (র-ফলা য-ফলা))
Grapheme Root distribution
Due to the large no. of possible class labels for the 167 unique grapheme roots, we chose to plot the top 10 and last 10 grapheme roots, based on the total number of images from the dataset in which the particular grapheme root appears.
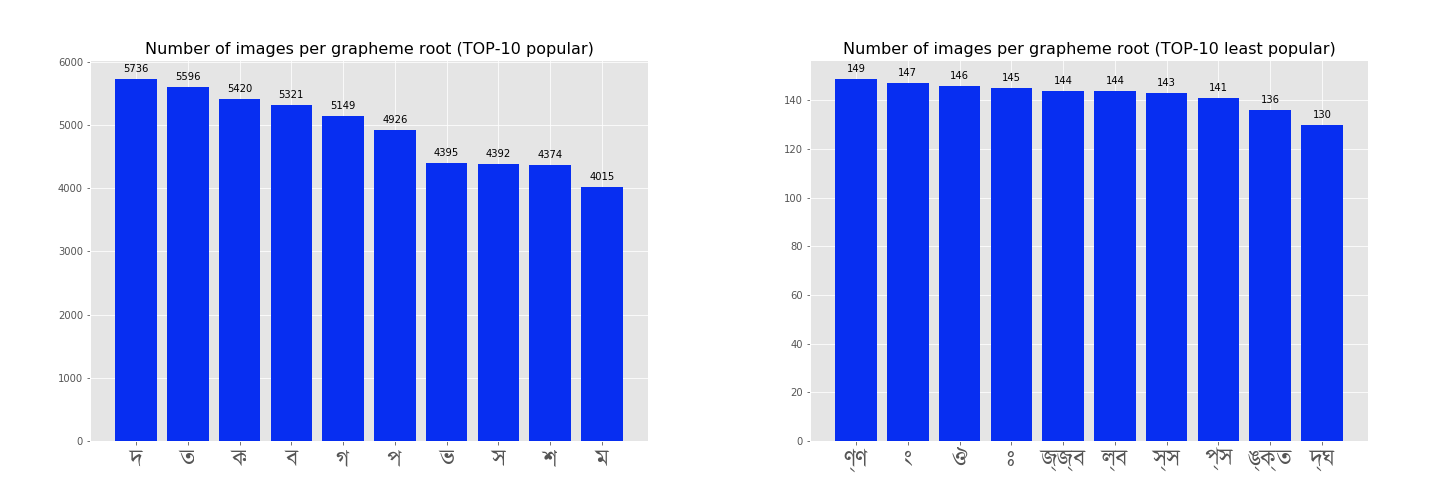
Here is the total distribution just for the big picture.
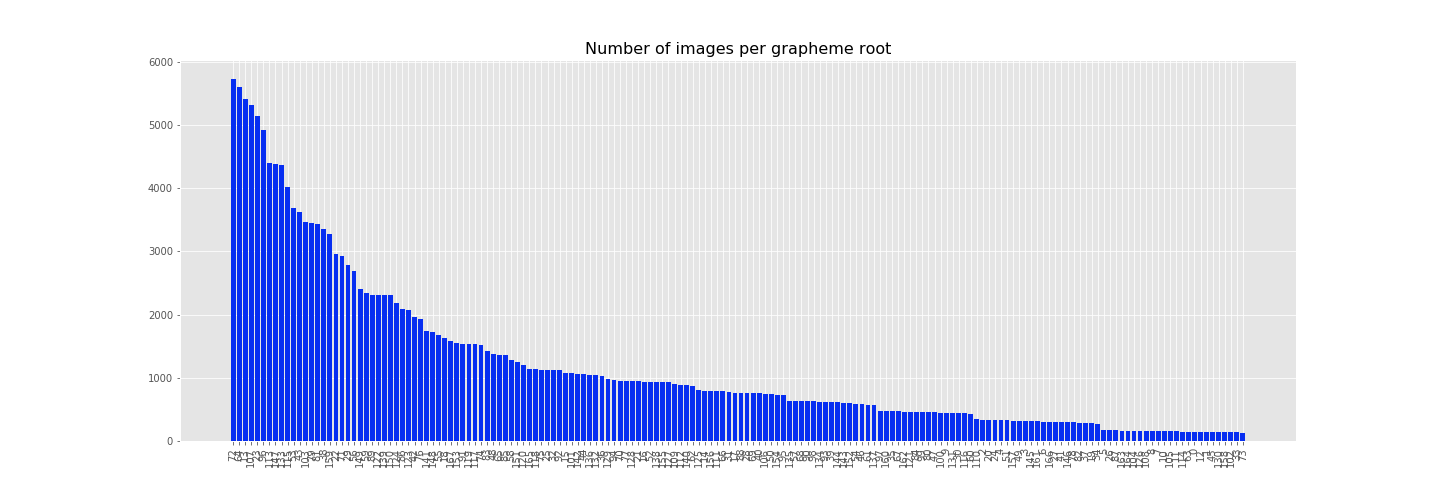
Visually, the top 10 common grapheme roots are:

While the bottom 10 (or least popular) grapheme roots are:

Vowel diacritics
Likewise in case of vowels (pictures below)

The distribution is still pretty skewed.
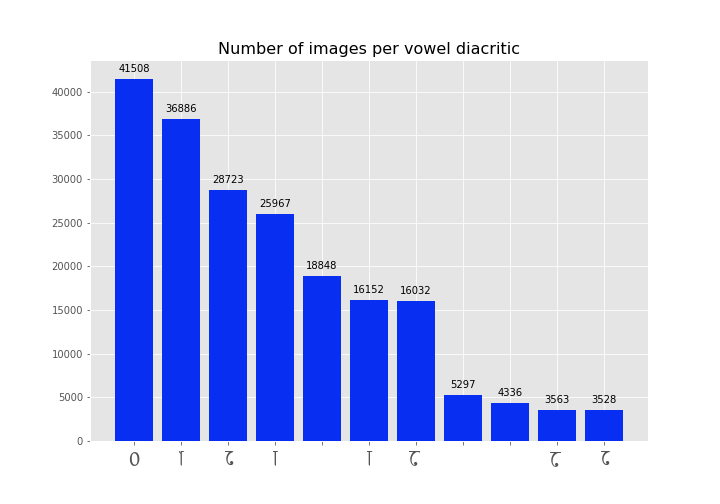 sorry for the fonts :( however, you can follow the order from the photo above
sorry for the fonts :( however, you can follow the order from the photo above
Consonant diacritics
The characters,

The distribution,
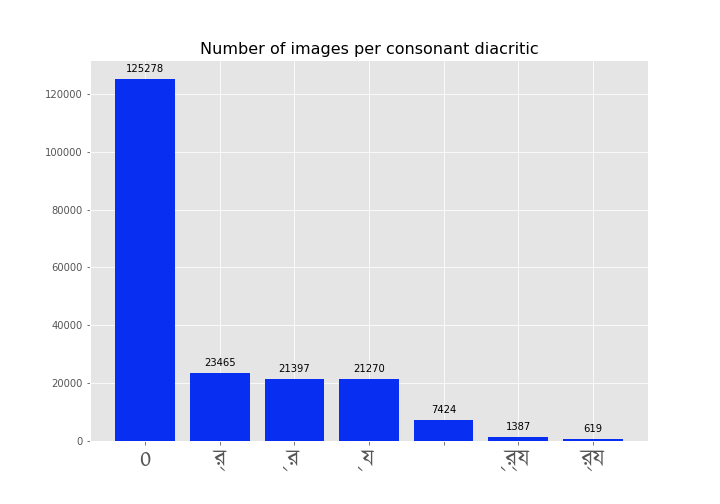 sorry for the fonts :( however, you can follow the order from the photo above
sorry for the fonts :( however, you can follow the order from the photo above
Both the distribution of the vowels and the consonants suggest that most graphemes are complete without using any diacritic. Particularly there seems to be very few consonants diacritic in practice (than vowels). This is pretty intuitive though, since, by definition a grapheme is most likely a conjunction of two consonants, hence the need for a third consonant is rare. Vowels on the other hand are more likely to be associated with a consonant (or a combination of two consonants).
Another major reason behind the imbalance of different targets and sub-classes might be ingrained within the nature of the bengali vocabulary. It is very natural for certain grapheme roots to be used more than certain esoteric ones, while some words (which are composed of graphemes ergo grapheme roots) are practically never used in colloquial parlance and some can only be found in ancient texts or used by logophilic authors.
Overall nothing surprising here, however, at this moment we are not sure how this would affect the training or whether this unbalance is something to be worried about. We’ll see.
Image Preprocessing
Here is a sample image from the data-set.

As we can see, the handwritten raw images, have several issues:
- The opacity of the images are not uniform. Some are brighter (1 and 3) while some darker (4). Certain images are scans from a different lighting conditions and thus have a gradient of gray noise flowing across (2), while some are out of the page (5).
- The most common difference is the off-centering of the graphemes compared to the canvas.
- There is optical noise, coming from the scans.
To alleviate these problems first-hand before sending the images to train, we use OpenCV-python⁴ to De-Noise -> Gray Scale -> Threshold -> Find text contours -> Resize the contoured image in a 64x64 square shape.
Remove Noise⁵: Here we use the Non-local means denoising, which uses data from the overall image rather than gaussian/median techniques which look at a region close to the pixel of interest for removing noise.
Grayscaling⁶: Since saving the image in a .png format introduces spurious channels (3 copies of the same data) from the original grayscale image, we convert it back into the original grayscale.
Thresholding⁷: In this method, all pixel values below a certain critical value is dropped to 0, while all values higher is set to 255. To choose the critical value, we use Otsu’s method of binarization, where the threshold value for each image is selected based on the histogram of the image (assuming a bimodal distribution).
Contouring and reshaping⁸: Once, all that is done, we use the contours (basically the area around the black text), put a bounding box around the main handwriting, cropping out the rest of the picture and then re-scaling it a 64x64 square.

Above you can see a sample of the before and after of the images after pre-processing.
Up Next ...
So far, we got our images ready for training. In the next few posts, we shall walk-through the following steps in the deep learning pipeline ahead.
Data Augmentation: A letter is still a letter with a bit of blur, it is the same even if it is rotated (not flipped BTW), and it is same even if it is written in terrible handwriting. We plan to use the Albumentation⁹ package in python to randomly add distortions to the training images while maintaining the same target labels. We expect that this should improve the learning process.
Neural Network Architecture: Needless to say, we plan to employ a convolutional NN architecture. As of now, this is the brief blueprint of the natal architecture. This deserves to be a full-post by itself.
See you next time…Stay tuned…
All codes for the project can be found in this github repository
Shout out to all the amazing people for uploading their notebooks. You guys guided us in the right direction.
References
- https://cs.brown.edu/courses/info/data2040/
- https://en.wikipedia.org/wiki/Bengali_language
- https://en.wikipedia.org/wiki/Bangladesh
- https://opencv.org/
- https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_photo/py_non_local_means/py_non_local_means.html
- https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_colorspaces/py_colorspaces.html
- https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_thresholding/py_thresholding.html?highlight=thresholding
- https://docs.opencv.org/trunk/d4/d73/tutorial_py_contours_begin.html
- https://github.com/albumentations-team/albumentations